;+
; Child class of INDEX_FILE, contains special functionality for dealing with spectral line data.
; This mostly entails the translation of sdfits data into contents of the index file.
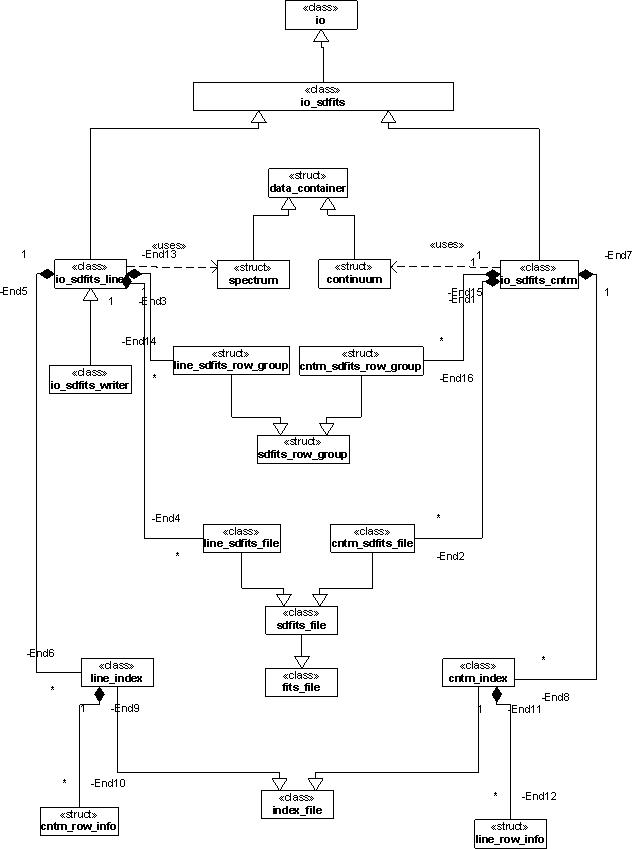
; See UML for all IO Classes, or
; INDEX UML for just index classes.
; This class is responsible for establishing the correct class for managing the
; row section of the index file, the translation between sdfits and index rows,
; translation from spectra to index rows, and provides the search gateway.
;
; @field if_filler object dedicating to filling if numbers for sdfits rows
;
; @file_comments
; Child class of INDEX_FILE, contains special functionality for dealing with spectral line data.
; This mostly entails the translation of sdfits data into contents of the index file.
; See UML for all IO Classes, or
; INDEX UML for just index classes.
; This class is responsible for establishing the correct class for managing the
; row section of the index file, the translation between sdfits and index rows,
; translation from spectra to index rows, and provides the search gateway.
; @private_file
;-
PRO line_index__define
ifile = { LINE_INDEX, inherits INDEX_FILE, $
if_filler:obj_new() $
}
END
;+
; Class Constructor - special formats for spectral line initialized here
; @private
;-
FUNCTION LINE_INDEX::init, _EXTRA=ex
compile_opt idl2, hidden
self.rows_class = "line_index_section"
self.if_filler = obj_new("if_filler")
r = self->INDEX_FILE::init(_EXTRA=ex)
return, r
END
;+
; Class Destructor - cleanup resources
; @private
;-
PRO LINE_INDEX::cleanup
compile_opt idl2, hidden
if obj_valid(self.if_filler) then obj_destroy, self.if_filler
self->INDEX_FILE::cleanup
END
;+
; Returns the speciall structure needed for spectral line data
; @returns line_row_info_strct structure
; @private
; -
FUNCTION LINE_INDEX::get_row_info_strct
@line_row_info
return, {line_row_info_strct}
END
;+
; This method searches the rows in the index file using the optional keywords.
; Not using any keywords returns all rows. Multiple keywords are combined with
; a logical AND.
;
; @param start {in}{optional}{type=long} where to start the range to search in
; @param finish {in}{optional}{type=long} where to stop the range to search in
;
; @keyword search {in}{optional}{type=array of longs} The row numbers
; to search, often this is the result of a previous search that you
; wish to refine.
; @keyword index {in}{optional}{type=long} index (zero-based)
; @keyword project {in}{optional}{type=string} project name
; @keyword file {in}{optional}{type=string} sdfits file
; @keyword extension {in}{optional}{type=long} sdfits extension number
; @keyword row {in}{optional}{type=long} sdfits row number
; @keyword source {in}{optional}{type=string} source name
; @keyword procedure {in}{optional}{type=string} procecure
; @keyword obsid {in}{optional}{type=string} obsid
; @keyword procscan {in}{optional}{type=string} procscan
; @keyword proctype {in}{optional}{type=string} proctype
; @keyword scan {in}{optional}{type=long} M&C scan number
; @keyword procseqn {in}{optional}{type=long} Procedure sequence number
; @keyword e2escan {in}{optional}{type=long} e2e scan numbers (not yet supported)
; @keyword polarization {in}{optional}{type=string} polarization
; @keyword plnum {in}{optional}{type=long } polarization index (zero-based)
; @keyword ifnum {in}{optional}{type=long } if number index (zero-based)
; @keyword feed {in}{optional}{type=long} feed name
; @keyword fdnum {in}{optional}{type=long} feed index number (zer0-based)
; @keyword int {in}{optional}{type=long} integraion number (zero-based)
; @keyword numchn {in}{optional}{type=long} total number of channels in the spectrum
; @keyword sig {in}{optional}{type=string} sig/ref state
; @keyword cal {in}{optional}{type=string} noise diode cal state
; @keyword wcalpos {in}{optional}{type=string} calposition
; @keyword sampler {in}{optional}{type=string} backend sampler name
; @keyword azimuth {in}{optional}{type=string} azimuth
; @keyword elevation {in}{optional}{type=string} elevation
; @keyword longitude {in}{optional}{type=string} longitude axis (ex:ra) value
; @keyword latitude {in}{optional}{type=string} latitude axis (ex:dec) value
; @keyword trgtlong {in}{optional}{type=string} target longitude (ex:ra) value
; @keyword trgtlat {in}{optional}{type=string} target latitude (ex:ra) value
; @keyword subref {in}{optional{type=long} subreflector state (0=moving,1,-1)
; @keyword lst {in}{optional}{type=string} LST
; @keyword centfreq {in}{optional}{type=string} center frequency
; @keyword restfreq {in}{optional}{type=string} rest frequency
; @keyword velocity {in}{optional}{type=string} source velocity
; @keyword freqint {in}{optional}{type=string} frequency interval
; (channel spacing)
; @keyword freqres {in}{optional}{type=string} frequency resolution
; (always > 0.0)
; @keyword dateobs {in}{optional}{type=string} date-time string
; @keyword timestamp {in}{optional}{type=string} the start of the scan
; @keyword bandwidth {in}{optional}{type=double} bandwidth
; @keyword exposure {in}{optional}{type=double} exposure
; @keyword tsys {in}{optional}{type=double} Tsys
; @keyword nsave {in}{optional}{type=long} nsave index number
; @keyword srow {in}{optional}{type=int} Starting row in index, used
; after scan_info has been used and the range of rows is known. Must
; be used with nrow.
; @keyword nrow {in}{optional}{type=int} Number of rows in index after
; srow, used after scan_info has been used and the range of rows is
; known. Must be used with nrow.
;
; @returns Array of longs, each element corresponding to a line number of the index file that matches the search
;
;-
FUNCTION LINE_INDEX::search_index, start, finish, SEARCH=search, INDEX=index, PROJECT=project, FILE=file, EXTENSION=extension, ROW=row, SOURCE=source, PROCEDURE=procedure, OBSID=obsid, PROCSCAN=procscan, PROCTYPE=proctype, E2ESCAN=e2escan, PROCSEQN=procseqn, SCAN=scan, POLARIZATION=polarization, PLNUM=plnum, IFNUM=ifnum, FEED=feed, FDNUM=fdnum, INT=int, NUMCHN=numchn, SIG=sig, CAL=cal, WCALPOS=wcalpos, SAMPLER=sampler, AZIMUTH=azimuth, ELEVATION=el, LONGITUDE=longitude, LATITUDE=latitude, TRGTLONG=trgtlong, TRGTLAT=trgtlat, SUBREF=subref, LST=lst, CENTFREQ=centfreq, RESTFREQ=restfreq, VELOCITY=velocity, FREQINT=freqint, FREQRES=freqres, DATEOBS=dateobs, TIMESTAMP=timestamp, BANDWIDTH=bandwidth, EXPOSURE=exposure, TSYS=tsys, NSAVE=nsave, srow=srow, nrow=nrow
compile_opt idl2
if (self.file_loaded eq 0) then begin
message, 'File not loaded, cannot search index. Use read_file method',/info
return, -1
endif
if n_elements(SEARCH) eq 0 then begin
if n_elements(srow) ne 0 and n_elements(nrow) ne 0 then begin
; limit to the selected rows
if srow lt 0 or (srow + nrow) gt n_elements(*self.row_lines) then begin
message,'Row selection can not proceed. Rows out of range',/info
return,-1
endif
search_result = lindgen(nrow) + srow
endif else begin
; init the search result to include all row indicies
search_result = lindgen(n_elements(*self.row_lines))
endelse
endif else begin
; init the search to include only previous results passed in
search_result = search
endelse
; if the start and finish parameters have been used, use them for limiting our search to a range.
; some methods always call search_index with start, finish set to the full range. If that's the
; case don't waste cpu time on this step
if n_elements(start) ne 0 or n_elements(finish) ne 0 then begin
if n_elements(start) eq 0 then start = 0
if n_elements(finish) eq 0 then finish = n_elements(*self.row_lines)-1
if start ne 0 or finish ne (n_elements(*self.row_lines)-1) then begin
search_result = self->search_range(start,finish,search_result)
endif
endif
if n_elements(search_result) eq 1 then begin
if search_result eq -1 then begin
return, search_result
endif
endif
; for each keyword, par down the search result for each criteria
count = n_elements(search_result)
if count gt 0 and n_elements(INDEX) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).index)[search_result],index,search_result,"INDEX",count)
endif
if count gt 0 and n_elements(PROJECT) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).project)[search_result],project,search_result,"PROJECT",count)
endif
if count gt 0 and n_elements(FILE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).file)[search_result],file,search_result,"FILE",count)
endif
if count gt 0 and n_elements(EXTENSION) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).extension)[search_result],extension,search_result,"EXTENSION",count)
endif
if count gt 0 and n_elements(ROW) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).row_num)[search_result],row,search_result,"ROW",count)
endif
if count gt 0 and n_elements(SOURCE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).source)[search_result],source,search_result,"SOURCE",count)
endif
if count gt 0 and n_elements(PROCEDURE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).procedure)[search_result],procedure,search_result,"PROCEDURE",count)
endif
if count gt 0 and n_elements(OBSID) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).obsid)[search_result],obsid,search_result,"OBSID",count)
endif
if count gt 0 and n_elements(PROCSCAN) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).procscan)[search_result],procscan,search_result,"PROCSCAN",count)
endif
if count gt 0 and n_elements(PROCTYPE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).proctype)[search_result],proctype,search_result,"PROCTYPE",count)
endif
if count gt 0 and n_elements(E2ESCAN) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).procseqn)[search_result],e2escan,search_result,"E2ESCAN",count)
endif
if count gt 0 and n_elements(PROCSEQN) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).procseqn)[search_result],procseqn,search_result,"PROCSEQN",count)
endif
if count gt 0 and n_elements(SCAN) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).mc_scan)[search_result],scan,search_result,"SCAN",count)
endif
if count gt 0 and n_elements(POLARIZATION) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).polarization)[search_result],polarization,search_result,"POLARIZATION",count)
endif
if count gt 0 and n_elements(PLNUM) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).pol_number)[search_result],plnum,search_result,"PLNUM",count)
endif
if count gt 0 and n_elements(IFNUM) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).if_number)[search_result],ifnum,search_result,"IFNUM",count)
endif
if count gt 0 and n_elements(FEED) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).feed)[search_result],feed,search_result,"FEED",count)
endif
if count gt 0 and n_elements(FDNUM) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).feed_number)[search_result],fdnum,search_result,"FDNUM",count)
endif
if count gt 0 and n_elements(INT) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).integration)[search_result],int,search_result,"INT",count)
endif
if count gt 0 and n_elements(NUMCHN) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).n_channels)[search_result],numchn,search_result,"NUMCHN",count)
endif
if count gt 0 and n_elements(SIG) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).sig_state)[search_result],sig,search_result,"SIG",count)
endif
if count gt 0 and n_elements(CAL) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).cal_state)[search_result],cal,search_result,"CAL",count)
endif
if count gt 0 and n_elements(WCALPOS) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).wcalpos)[search_result],wcalpos,search_result,"WCALPOS",count)
endif
if count gt 0 and n_elements(SAMPLER) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).sampler)[search_result],sampler,search_result,"SAMPLER",count)
endif
if count gt 0 and n_elements(AZIMUTH) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).azimuth)[search_result],azimuth,search_result,"AZIMUTH",count)
endif
if count gt 0 and n_elements(ELEVATION) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).elevation)[search_result],elevation,search_result,"ELEVATION",count)
endif
if count gt 0 and n_elements(LONGITUDE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).longitude_axis)[search_result],longitude,search_result,"LONGITUDE",count)
endif
if count gt 0 and n_elements(LATITUDE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).latitude_axis)[search_result],latitude,search_result,"LATITUDE",count)
endif
if count gt 0 and n_elements(TRGTLONG) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).target_longitude)[search_result],trgtlong,search_result,"TRGTLONG",count)
endif
if count gt 0 and n_elements(TRGTLAT) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).target_latitude)[search_result],trgtlat,search_result,"TRGTLAT",count)
endif
if count gt 0 and n_elements(SUBREF) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).subref)[search_result],subref,search_result,"SUBREF",count)
endif
if count gt 0 and n_elements(LST) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).lst)[search_result],lst,search_result,"LST",count)
endif
if count gt 0 and n_elements(CENTFREQ) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).center_frequency)[search_result],centfreq,search_result,"CENTFREQ",count)
endif
if count gt 0 and n_elements(RESTFREQ) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).rest_frequency)[search_result],restfreq,search_result,"RESTFREQ",count)
endif
if count gt 0 and n_elements(VELOCITY) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).source_velocity)[search_result],velocity,search_result,"VELOCITY",count)
endif
if count gt 0 and n_elements(FREQINT) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).freqint)[search_result],freqint,search_result,"FREQINT",count)
endif
if count gt 0 and n_elements(FREQRES) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).freqres)[search_result],freqres,search_result,"FREQRES",count)
endif
if count gt 0 and n_elements(DATEOBS) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).date_obs)[search_result],dateobs,search_result,"DATEOBS",count)
endif
if count gt 0 and n_elements(TIMESTAMP) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).timestamp)[search_result],timestamp,search_result,"TIMESTAMP",count)
endif
if count gt 0 and n_elements(BANDWIDTH) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).bandwidth)[search_result],bandwidth,search_result,"BANDWIDTH",count)
endif
if count gt 0 and n_elements(EXPOSURE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).exposure)[search_result],exposure,search_result,"EXPOSURE",count)
endif
if count gt 0 and n_elements(TSYS) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).tsys)[search_result],tsys,search_result,"TSYS",count)
endif
if count gt 0 and n_elements(NSAVE) ne 0 then begin
search_result = self->refine_search(((*self.row_lines).nsave)[search_result],nsave,search_result,"NSAVE",count)
endif
return, search_result
END
;+
; Translates raw sdfits rows into the rows to be written to the index file. This is where
; all the algorithms are implemented for determining if and integration numbers.
; @param rows {in}{type=array} array of structs representing sdfits rows
; @param proj {in}{type=string} project id shared by all rows
; @param file_name {in}{type=string} file location shared by all rows
; @param ext {in}{type=long} extension location shared by all rows
; @param missing {in}{type=array} string array of columns missing from the sdfits file
; @param virtuals {in}{type=struct} key-value pairs from sdfits extension header (not including col descriptions)
; @param start {in}{type=long} row number that these rows start at 4
; @returns arrays of structures representing lines to be written to index file
; @uses INDEX_FILE::get_row_info_strct
; @uses LINE_INDEX::get_integreation_number
; @uses LINE_INDEX::get_if_numbers
; @uses INDEX_FILE::get_row_value
;-
FUNCTION LINE_INDEX::parse_extension_rows, rows, proj, file_name, ext, missing, virtuals, start
compile_opt idl2
names = {row:ptr_new(tag_names(rows[0])),missing:ptr_new(missing),virtuals:ptr_new(tag_names(virtuals))}
info = make_array(n_elements(rows),value=self->get_row_info_strct())
; defaults for missing columns in sdfits row
di = -1L
df = 0.0
dd = 0.0D
ds = ''
; can proj be used or should we use what's in the rows
projOK = size(proj,/type) eq 7
; find the primary ID to use in constructing the index
; use timestamp if available, else scan
ind = where("TIMESTAMP" eq missing, cnt)
if cnt eq 0 then begin
; the TIMESTAMP column was found
ids = rows.timestamp
endif else begin
; we will have to use the scan numbers
ids = rows.scan
endelse
; start indexing from the current number of rows
firstIndex = self.rows->get_num_rows()
nrows = n_elements(rows)
if nrows gt 1000 then progress_bar=1 else progress_bar=0
if progress_bar then begin
total_bar = '__________'
step_size = long(n_elements(rows)/10)
step = 0
print, "Parsing scan info:"
print, total_bar
endif
; loop until out of rows to process
startRow = 0
while (startRow lt nrows) do begin
id = ids[startRow]
lastRow = startRow + 1
while (lastRow lt nrows) do begin
if ids[lastRow] ne id then break
lastRow++
endwhile
lastRow--
if self.debug then print, "ID: "+string(id)
if self.debug then print, "rows to process: "+string(lastRow-startRow+1)
; run algorithms (if needed) for determining if, integration, ; polarization, and feed numbers
index_start = startRow + firstIndex
index_end = lastRow + firstIndex
ind = where("INT" eq missing, cnt)
if cnt ne 0 then begin
ints = self->get_integration_numbers(rows[startRow:lastRow],names)
endif else begin
ints = lonarr(n_elements(rows[startRow:lastRow]))
endelse
ind = where("IFNUM" eq missing, cnt)
if cnt ne 0 then begin
ifs = self->get_if_numbers(rows[startRow:lastRow],names,ints,index_start,index_end)
endif else begin
ifs = lonarr(n_elements(rows[startRow:lastRow]))
endelse
ind = where("FDNUM" eq missing, cnt)
if cnt ne 0 then begin
feeds = self->get_feed_numbers(rows[startRow:lastRow],names)
endif else begin
feeds = lonarr(n_elements(rows[startRow:lastRow]))
endelse
ind = where("PLNUM" eq missing, cnt)
if cnt ne 0 then begin
pols = self->get_polarization_numbers(rows[startRow:lastRow],names)
endif else begin
pols = lonarr(n_elements(rows[startRow:lastRow]))
endelse
if self.debug then begin
print, 'ints, ifs, beams, and pols:'
print, ints
print, ifs
print, feeds
print, pols
endif
; for each row in the FITS file for this id, create its line in the index
for j=0,n_elements(ints)-1 do begin
row_index = j + startRow
row = rows[row_index]
row_info = self->get_row_info_strct()
; we probably aren't passed a structure with the huge DATA column
; retrieve the number of channels from the dimensions keyword
; This is sdfits ver. dependent - better design for this?
cnt = 0
ind = where('TDIM7' eq *names.row,cnt)
if cnt ne 0 then begin
dims = self->get_row_value(row,'TDIM7',virtuals,names,'(0,1,1,1)')
endif else begin
dims = self->get_row_value(row,'TDIM6',virtuals,names,'(0,1,1,1)')
endelse
num_chans = self->get_num_chans_from_dims(dims)
; copy basic info
; index number is zero-based
row_info.index = row_index + firstIndex
row_info.project = projOK ? proj : strtrim(self->get_row_value(row,'PROJID',virtuals,names,'unknown'))
row_info.file = file_name
row_info.extension = ext
row_info.mc_scan = self->get_row_value(row,'SCAN',virtuals,names,di)
row_info.row_num = row_index + start
source = self->get_row_value(row,'OBJECT',virtuals,names,'source')
row_info.source = strtrim(source,2)
obsmode = self->get_row_value(row,'OBSMODE',virtuals,names,'proc')
row_info.procedure = self->get_procedure_from_obsmode(obsmode)
row_info.obsid = strtrim(self->get_row_value(row,'OBSID',virtuals,names,ds),2)
row_info.procscan = strtrim(self->get_row_value(row,'PROCSCAN',virtuals,names,'Unknown'),2)
row_info.proctype = strtrim(self->get_row_value(row,'PROCTYPE',virtuals,names,'Unknown'),2)
row_info.procseqn = self->get_row_value(row,'PROCSEQN',virtuals,names,0)
pol = self->get_row_value(row,'CRVAL4',virtuals,names,0)
row_info.polarization = self->translate_polarization(pol)
row_info.feed = self->get_row_value(row,'FEED',virtuals,names,di)
row_info.n_channels = num_chans
row_info.sig_state = self->get_row_value(row,'SIG',virtuals,names,'T')
row_info.cal_state = self->get_row_value(row,'CAL',virtuals,names,'T')
row_info.wcalpos = self->get_row_value(row,'CALPOSITION',virtuals,names,'Unknown')
row_info.sampler = strtrim(self->get_row_value(row,'SAMPLER',virtuals,names,'??'),2)
row_info.azimuth = self->get_row_value(row,'AZIMUTH',virtuals,names,dd)
row_info.elevation = self->get_row_value(row,'ELEVATIO',virtuals,names,dd)
row_info.longitude_axis = self->get_row_value(row,'CRVAL2',virtuals,names,dd)
row_info.latitude_axis = self->get_row_value(row,'CRVAL3',virtuals,names,dd)
row_info.target_longitude = self->get_row_value(row,'TRGTLONG',virtuals,names,dd)
row_info.target_latitude = self->get_row_value(row,'TRGTLAT',virtuals,names,dd)
row_info.subref = self->get_row_value(row,'SUBREF_STATE',virtuals,names,dd)
row_info.lst = self->get_row_value(row,'LST',virtuals,names,dd)
row_info.freqint = self->get_row_value(row,'CDELT1',virtuals,names,dd)
row_info.freqres = abs(self->get_row_value(row,'FREQRES',virtuals,names,dd))
ref_chan = self->get_row_value(row,'CRPIX1',virtuals,names,di)
ref_freq = self->get_row_value(row,'CRVAL1',virtuals,names,dd)
row_info.center_frequency = self->get_center_frequency(ref_freq, ref_chan, row_info.freqint, row_info.n_channels)
row_info.rest_frequency = self->get_row_value(row,'RESTFREQ',virtuals,names,dd)
row_info.source_velocity = self->get_row_value(row,'VELOCITY',virtuals,names,dd)
row_info.date_obs = self->get_row_value(row,'DATE_OBS',virtuals,names,'DD:MM:YYT00:00:00' )
row_info.timestamp = strtrim(self->get_row_value(row,'TIMESTAMP',virtuals,names,'DD_MM_YY_00:00:00' ),2)
row_info.bandwidth = self->get_row_value(row,'BANDWID',virtuals,names,dd )
row_info.exposure = self->get_row_value(row,'EXPOSURE',virtuals,names,dd )
row_info.tsys = self->get_row_value(row,'TSYS',virtuals,names,dd)
; values only to be found in an file created by gbtidl
row_info.nsave = self->get_row_value(row,'NSAVE',virtuals,names,-1)
; fill in derived info
row_info.integration = self->get_row_value(row,'INT',virtuals,names,ints[j])
row_info.if_number = self->get_row_value(row,'IFNUM',virtuals,names,ifs[j])
row_info.feed_number = self->get_row_value(row,'FDNUM',virtuals,names,feeds[j])
row_info.pol_number = self->get_row_value(row,'PLNUM',virtuals,names,pols[j])
; append this line to list of lines
info[row_index] = row_info
; update the progress bar
if progress_bar then begin
if step eq step_size then begin
step = 0
print, format='("X",$)'
endif else begin
step += 1
endelse
endif
endfor ; for each row of this ID
startRow = lastRow + 1
endwhile ; for loop through IDs
; terminate progress bar
if progress_bar then print, format='(/)'
; clean up
if ptr_valid(names.row) then ptr_free,names.row
if ptr_valid(names.missing) then ptr_free,names.missing
if ptr_valid(names.virtuals) then ptr_free,names.virtuals
return, info
END
;+
; Appends row info to an index file, given a group of rows from sdfits files. Used
; for first loading in an sdfits file
; @param ext_rows {in}{type=array} array of sdfits rows
; @param proj {in}{type=string} project shared by all rows
; @param file_name {in}{type=string} file location shared by all extensions
; @param ext {in}{type=long} extension location shared by all extensions
; @param missing {in}{type=array} string array of columns missing from the ext_rows param
; @param virtuals {in}{type=struct} keywords from extension header not describing columns
; @param start_row {in}{type=long} where these spectra start in the extension
; @uses LINE_INDEX::spectra_to_info
; @uses LINE_INDEX::update_index_file
;-
PRO LINE_INDEX::update_file, ext_rows, proj, file_name, ext, missing, virtuals, start_row
compile_opt idl2
if (n_params() eq 7) then start=start_row else start=0
rows_info = self->parse_extension_rows(ext_rows,proj,file_name,ext, missing, virtuals, start)
self->update_index_file, rows_info
END
;+
; Algorithm for assigning if numbers for each row in the index file (zero-based). First, only first integrations
; are looked at. Of these, only where the SIG column is True are used. Finally of these, unique
; combinations of (CRVAL1, CTYPE1, CDELT1, and CRPIX1) columns are used to compute the number of ifs
; in the scan. These if numbers are assigned to where those unique combinations occur, and the unassigned
; numbers are 'back filled' using the integration numbers as a guide.
; @param scan_rows {in}{type=array} array of sdfits rows for just one scan
; @param names {in}{type=struct} structure containing pointers to names of sdfits columns, missing columns, and keywords
; @param ints {in}{type=array} integration numbers for each row
; @param index_start {in}{type=long} the starting index num for these rows
; @param index_end {in}{type=long} the ending index num for these rows
; @returns an array for if numbers of each row in index file for this scan (ex: [0,0,1,1,2,2,0,0,1,1,2,2,,...])
; @uses INDEX_FILE::get_col_variability
; @private
;-
FUNCTION LINE_INDEX::get_if_numbers, scan_rows, names, ints, index_start, index_end
compile_opt idl2
return, self.if_filler->get_if_numbers(scan_rows, names, ints, index_start, index_end)
END
;+
; Algorithm for determining integration numbers (0-based), given the sdfits rows of a scan.
; This is simple: just use the DATE-OBS column values.
; @param scan_rows {in}{type=array} array of sdfits rows for just one scan
; @param names {in}{type=struct} structure containing pointers to names of sdfits columns, missing columns, and keywords
; @returns an array for integration numbers of each row in index file for this scan (ex: [0,0,1,1,2,2,3,3,...])
; @uses INDEX_FILE::get_col_variability
; @private
;-
FUNCTION LINE_INDEX::get_integration_numbers, scan_rows, names
compile_opt idl2
; match up each date_obs value with an integer integration number
; we have to assume that the date_obs column is included
dObs = scan_rows.date_obs
n_rows = n_elements(dObs)
; get unique date_obs values - can not assume already sorted
dObsUnique = dObs[uniq(dObs,sort(dObs))]
n_ints = n_elements(dObsUnique)
ints = intarr(n_rows)
for i=0,(n_ints-1) do begin
ints[where(dObs eq dObsUnique[i])] = i
endfor
return, ints
END
;+
; Algorithm for determining feed numbers (0-based), given the sdfits rows of a scan.
; @param scan_rows {in}{type=array} array of sdfits rows for just one scan
; @param names {in}{type=struct} structure containing pointers to names of sdfits columns, missing columns, and keywords
; @returns an array for feed numbers of each row in index file for this scan (ex: [0,0,1,1,2,2,3,3,...])
; @uses INDEX_FILE::get_col_variability
; @private
;-
FUNCTION LINE_INDEX::get_feed_numbers, scan_rows, names
compile_opt idl2
; how many different beam numbers are there?
n_beams = self->get_col_variability(scan_rows,'FEED',names,1)
n_rows = n_elements(scan_rows)
if n_beams eq 1 then begin
; either there is just one FEED value used, or FEED column is absent:
; beam numbers are all zeros
beam_nums = lonarr(n_rows)
endif else begin
; we can assume that the feed column is included
beams = scan_rows.feed
u_beams = beams[uniq(beams, sort(beams))]
beam_nums = lonarr(n_rows)
for i=0,n_elements(u_beams)-1 do begin
j = where(beams eq u_beams[i])
beam_nums[j] = i
endfor
endelse
return, beam_nums
END
;+
; Returns a structure or array of structures that contains info about
; the scan number given, such as scan number, procedure name, number
; of integrations, ifs, etc.. One element in the array for each
; unique TIMESTAMP value for all rows having that scan number.
; @param scan_number {in}{type=long} scan number information is
; queried for
; @param file {in}{optional}{type=string} Limit the search for the
; scan number to a specific file name.
; @keyword count {out}{type=integer} The number of elements of the
; returned array of scan_info structures.
; @keyword quiet {in}{optional}{type=boolean} When set, suppress most
; error messages.
;
; @returns Array of structures containing info on scan, returns -1 on
; failure.
;-
FUNCTION LINE_INDEX::get_scan_info, scan_number, file, count=count, quiet=quiet
compile_opt idl2
count = 0
rows = self->search_for_row_info(scan=scan_number,file=file)
if (size(rows,/dimension) eq 0) then begin
if not keyword_set(quiet) then begin
if n_elements(file) eq 0 then begin
message, 'Scan number not found: '+string(scan_number),/info
endif else begin
message, 'Scan number not found in ' + file + " : " +strtrim(string(scan_number),2),/info
endelse
endif
return, -1
endif
uniqueTimes = rows[uniq(rows.timestamp)].timestamp
count = 0
; two passes, first gets the counts of things that determine array
; sizes and the second actually fills in the scan info structures
maxPlnum = 0
maxIfnum = 0
maxFdnum = 0
for i=0,(n_elements(uniqueTimes)-1) do begin
theseRowsIndex = where(rows.timestamp eq uniqueTimes[i],numRowsToHandle)
theseTimesRows = rows[theseRowsIndex]
seqDiff = theseTimesRows[0].index
fullSeq = lindgen(numRowsToHandle)
while (numRowsToHandle gt 0) do begin
; handle sequential indexes in each pass in this loop
sequentialRows = where((theseTimesRows.index-fullSeq) eq seqDiff,seqRowCount)
theseRows = theseTimesRows[sequentialRows]
; assumes all fdnums, ifnums, plnums, samplers present at first integration
firstIntRows = theseRows[where(theseRows.integration eq theseRows[0].integration)]
fdnums = self->get_uniques(firstIntRows.feed_number)
maxFdnum = max([maxFdnum,fdnums])
nf = n_elements(fdnums)
plnums = self->get_uniques(firstIntRows.pol_number)
maxPlnum = max([maxPlnum,plnums])
np = n_elements(plnums)
ifnums = self->get_uniques(firstIntRows.if_number)
maxIfnum = max([maxIfnum,ifnums])
nif = n_elements(ifnums)
nsamp = n_elements(self->get_uniques(firstIntRows.sampler))
; this must be checked at all integrations
nwcal = n_elements(self->get_uniques(theseRows.wcalpos))
thisRowStart = theseRowsIndex[sequentialRows[0]]
if count eq 0 then begin
nfeeds = nf
npols= np
nifs = nif
nsamps = nsamp
rowStart = thisRowStart
nrows = seqRowCount
nwcals = nwcal
endif else begin
nfeeds = [nfeeds,nf]
npols = [npols,np]
nifs = [nifs,nif]
nsamps = [nsamps,nsamp]
rowStart = [rowStart,thisRowStart]
nrows = [nrows,seqRowCount]
nwcals = [nwcals,nwcal]
endelse
count += 1
; prepare for next loop, if necessary
numRowsToHandle = numRowsToHandle - seqRowCount
if numRowsToHandle gt 0 then begin
nextSeqStart = sequentialRows[seqRowCount-1]+1
seqDiff = theseTimesRows[nextSeqStart].index - fullSeq[nextSeqStart]
endif
endwhile
endfor
maxNfeeds = max(nfeeds)
maxNpols = max(npols)
maxNif = max(nifs)
maxNsamp = max(nsamps)
maxNwcal = max(nwcals)
scan_info_struct = {scan:0L,procseqn:0L,timestamp:'',file:'', procedure:'',$
n_integrations:0L, n_feeds:0L, fdnums:lonarr(maxNfeeds), $
n_ifs:0L, ifnums:lonarr(maxNif), $
n_cal_states:0L, n_sig_states:0L, n_switching_states:0L, $
n_wcalpos:0L, wcalpos:strarr(maxNwcal), $
n_polarizations:0L, polarizations:strarr(maxNpols), $
plnums:lonarr(maxNpols), feeds:lonarr(maxNfeeds), $
bandwidths:dblarr(maxNif), $
index_start:0L, nrecords:0L, n_samplers:0L, $
n_channels:lonarr(maxNsamp), $
samplers:strarr(maxNsamp), n_sampints:lonarr(maxNsamp), $
iftable:intarr(maxIfnum+1,maxFdnum+1,maxPlnum+1)}
scan_info = replicate(scan_info_struct,count)
; note that IDL will drop any
; degenerate trailing axes in
; scan_info.iftable so care must be
; taken when using the shape from that
; field
for j=0,(count-1) do begin
thisScanInfo = scan_info[j]
theseRowsIndex = lindgen(nrows[j]) + rowStart[j]
theseRows = rows[theseRowsIndex]
; find all of the integrations
integrations = self->get_uniques(theseRows.integration)
; the first integration should have all feeds, polarizations
; spectral windows, samplers, sig states, cal states, and files
firstIntRows = theseRows[where(theseRows.integration eq integrations[0])]
; init arrays in structure
for i=0,(maxNfeeds-1) do thisScanInfo.feeds[i] = -1
for i=0,(maxNpols-1) do thisScanInfo.plnums[i] = -1
; strings should already be initialized to ''
; bandwidths already initialized to 0.0
feeds = self->get_uniques(firstIntRows.feed)
fdnums = self->get_uniques(firstIntRows.feed_number)
plnums = self->get_uniques(firstIntRows.pol_number)
pols = strarr(n_elements(plnums))
ifs = self->get_uniques(firstIntRows.if_number)
samplers = self->get_uniques(firstIntRows.sampler)
; wcalpos can vary throughout the scan
wcalpos = self->get_uniques(theseRows.wcalpos)
thisScanInfo.wcalpos[0:(n_elements(wcalpos)-1)] = wcalpos
; to help find this scan, no matter what
thisScanInfo.index_start = theseRows[0].index
thisScanInfo.nrecords = nrows[j]
; this info is constant for scan
thisScanInfo.scan = theseRows[0].mc_scan
thisScanInfo.procseqn = theseRows[0].procseqn
thisScanInfo.timestamp = theseRows[0].timestamp
; there might be multiple files involved in this scan
thisScanInfo.file = self->file_match(firstIntRows.file)
thisScanInfo.procedure = theseRows[0].procedure
; collect info about scan
; this is always the max number of integrations if they vary by sampler
; assume sorted by integration and fish out the last one
; number of integrations is just 1 more than the last
; integration number
thisScanInfo.n_integrations = integrations[n_elements(integrations)-1]+1
; some values were learned and recorded in the first pass
thisScanInfo.n_feeds = nfeeds[j]
thisScanInfo.n_ifs = nifs[j]
thisScanInfo.n_polarizations = npols[j]
thisScanInfo.n_samplers = nsamps[j]
thisScanInfo.n_wcalpos = nwcals[j]
n_sigs = n_elements(self->get_uniques(firstIntRows.sig_state))
n_cals = n_elements(self->get_uniques(firstIntRows.cal_state))
thisScanInfo.n_switching_states = n_sigs*n_cals
thisScanInfo.n_cal_states = n_cals
thisScanInfo.n_sig_states = n_sigs
for i=0,(npols[j]-1) do begin
thisScanInfo.plnums[i] = plnums[i]
indx = where(firstIntRows.pol_number eq plnums[i])
thisScanInfo.polarizations[i] = firstIntRows[indx[0]].polarization
endfor
thisScanInfo.fdnums[0:(nfeeds[j]-1)] = fdnums
thisScanInfo.feeds[0:(nfeeds[j]-1)] = feeds
thisScanInfo.ifnums[0:(nifs[j]-1)] = ifs
for i=0,(nifs[j]-1) do begin
indx = where(firstIntRows.if_number eq ifs[i])
thisScanInfo.bandwidths[i] = firstIntRows[indx[0]].bandwidth
endfor
nSamp = n_elements(samplers)
thisScanInfo.samplers[0:(n_elements(samplers)-1)] = samplers
; this is faster than doing
; "where" on each sampler for
; the whole record for long scans
; but will be slower if some samplers
; have far fewer integrations in them
; than the other samplers.
tmpSampler = samplers
; assumes rows are sorted by integration number
; true for raw data, which is what
; this is designed for
for intIndx=(n_elements(integrations)-1),0,-1 do begin
thisInt = integrations[intIndx]
unfound = 0
theseIntRows = theseRows[where(theseRows.integration eq thisInt)]
theseSamplers = self->get_uniques(theseIntRows.sampler)
for i=0,(nsamps[j]-1) do begin
thisSampler = tmpSampler[i]
if strlen(thisSampler) gt 0 then begin
samplerRowsIndx = where(theseIntRows.sampler eq thisSampler,sampCount)
if sampCount gt 0 then begin
; found
thisScanInfo.n_channels[i] = theseIntRows[samplerRowsIndx[0]].n_channels
thisScanInfo.n_sampints[i] = thisInt+1
; don't look for it again
tmpSampler[i] = ''
endif else begin
; not found in this integration
unfound = unfound + 1
endelse
endif
endfor
if unfound eq 0 then break
endfor
; fill in iftable: feed, then ifnum, then pols
for i=0,(nfeeds[j]-1) do begin
; should share same feed_number
indx = where(firstIntRows.feed eq feeds[i])
feedRows = firstIntRows[indx]
feed_number = feedRows[0].feed_number
theseIFNums = self->get_uniques(feedRows.if_number)
for if_i=0,(n_elements(theseIFNums)-1) do begin
if_number = theseIFNums[if_i]
if_indx = where(feedRows.if_number eq if_number)
pl_nums = self->get_uniques(feedRows[if_indx].pol_number)
thisScanInfo.iftable[if_number, feed_number, pl_nums] = 1
endfor
endfor
scan_info[j] = thisScanInfo
endfor
return, scan_info
END
;+
; Appends row info to an index file, given a group of spectra. Used for when these
; spectra have been written to an sdifts file.
; @param spectra {in}{type=array} array of spectrum data containers
; @param file_name {in}{type=string} file location shared by all extensions
; @param extension {in}{type=long} extension location shared by all extensions
; @param start_row {in}{type=long} where these spectra start in the extension, should be the current number of rows in extension
; @uses LINE_INDEX::spectra_to_info
; @uses LINE_INDEX::update_index_file
;-
PRO LINE_INDEX::update_with_spectra, spectra, file_name, extension, start_row
compile_opt idl2
if (n_params() eq 4) then start=start_row else start=0
rows_info = self->spectra_to_info(spectra, file_name, extension, start)
self->update_index_file, rows_info
END
;+
; Replaces a line specified by index number in the index rows section, with information derived
; from a given spectral line data container, and that specturm's location (sdfits file, ext, row)
; Used when a row has been rewritten in an sdfits file with a new spectra (via nsave, for example).
; @param spectrum {in}{type=array} spectral line data container
; @param file_name {in}{type=string} file location where spectral line was written
; @param extension {in}{type=long} extension location where this spectrum was written
; @param row_num {in}{type=long} row number where this spectrum was written
; @uses LINE_INDEX::spectra_to_info
;-
PRO LINE_INDEX::replace_with_spectrum, index, spectrum, file_name, extension, row_num
compile_opt idl2
row_info = self->spectrum_to_info(spectrum, index, file_name, extension, row_num)
self.rows->overwrite_row, index, row_info
self.row_lines = self.rows->get_rows_ptr()
END
;+
; Translates information in a single spectral line data container, along with this data containers
; location in the sdfits file and index file, into a line in the rows section of the index file
; @param spectrum {in}{type=struct} spectrum data container
; @param index {in}{type=long} index number that this row will have in index file
; @param file_name {in}{type=string} file that this spectrum is from
; @param extension {in}{type=long} extension that this spectrum are from
; @param row_num {in}{type=long} the row that this spectrum is from
; @uses INDEX_FILE::get_row_info_strct
; @returns structure representing a row in the index file
; @private
;-
FUNCTION LINE_INDEX::spectrum_to_info, spectrum, index, file_name, extension, row_num
compile_opt idl2
row_info = self->get_row_info_strct()
; copy over basic info
row_info.index = index
row_info.project = spectrum.projid
row_info.file = file_name
row_info.extension = extension
row_info.row_num = row_num
row_info.mc_scan = spectrum.scan_number
row_info.source = spectrum.source
row_info.procedure = spectrum.procedure
row_info.obsid = spectrum.obsid
row_info.procscan = spectrum.procscan
row_info.proctype = spectrum.proctype
row_info.procseqn = spectrum.procseqn
row_info.polarization = spectrum.polarization
row_info.pol_number = spectrum.polarization_num
row_info.feed = spectrum.feed
row_info.feed_number = spectrum.feed_num
if (spectrum.sig_state eq 1) then sig = 'T' else sig = 'F'
row_info.sig_state = sig
if (spectrum.cal_state eq 1) then cal = 'T' else cal = 'F'
row_info.cal_state = cal
row_info.wcalpos = spectrum.calposition
row_info.sampler = spectrum.sampler_name
row_info.integration =spectrum.integration
row_info.n_channels = n_elements(*spectrum.data_ptr)
row_info.if_number = spectrum.if_number
row_info.date_obs = spectrum.date ; + time info!
row_info.timestamp = spectrum.timestamp
row_info.azimuth = spectrum.azimuth
row_info.elevation = spectrum.elevation
row_info.longitude_axis = spectrum.longitude_axis
row_info.latitude_axis = spectrum.latitude_axis
row_info.target_longitude = spectrum.target_longitude
row_info.target_latitude = spectrum.target_latitude
row_info.subref = spectrum.subref_state
row_info.lst = spectrum.lst
row_info.center_frequency = spectrum.center_frequency
row_info.rest_frequency = spectrum.line_rest_frequency
row_info.source_velocity = spectrum.source_velocity
row_info.freqint = spectrum.frequency_interval
row_info.freqres = spectrum.frequency_resolution
row_info.bandwidth = spectrum.bandwidth
row_info.exposure = spectrum.exposure
row_info.tsys = spectrum.tsys
row_info.nsave = spectrum.nsave
return, row_info
END
;+
; Translates spectral line data containers directly into the rows to be written to index file.
; No specail coding here, since an index file was used to create this data container at some point.
; This assumes that the spectra have been recenlty appended to the file in param file_name.
; @param spectra {in}{type=array} array of spectrum data containers
; @param file_name {in}{type=string} file that these spectra are from
; @param extension {in}{type=long} extension that these spectra are from
; @param start {in}{type=long} the row at which these spectra start in their file-extension location, should be the current number of rows in extension
; @uses INDEX_FILE::get_row_info_strct
; @uses LINE_INDEX::spectrum_to_info
; @returns structures representing a row in the index file
; @private
;-
FUNCTION LINE_INDEX::spectra_to_info, spectra, file_name, extension, start
compile_opt idl2
info = make_array(n_elements(spectra),value=self->get_row_info_strct())
new_index = self.rows->get_num_rows()
for i = 0, n_elements(spectra)-1 do begin
row_info = self->get_row_info_strct()
row_info = self->spectrum_to_info(spectra[i], new_index, file_name, extension, (i+start))
new_index = new_index + 1
; append this line to list of lines
info[i] = row_info
endfor
return, info
END
;+
; Makes object verbose
;-
PRO LINE_INDEX::set_debug_on
compile_opt idl2
self->INDEX_FILE::set_debug_on
if obj_valid(self.if_filler) then self.if_filler->set_debug_on
END
;+
; Makes object quiet
PRO LINE_INDEX::set_debug_off
compile_opt idl2
self->INDEX_FILE::set_debug_off
if obj_valid(self.if_filler) then self.if_filler->set_debug_off
END
;+
; Finds the number and sizes of extensions for a file listed in the index file, according to the index file.
; @param file_name {in}{type=string} file whose properties are being queried
; @param extensions {out}{type=long} number of extensions for this file
; @param num_rows {out}{type=array} array showing how many rows in each extension for this file
; @private
;-
PRO LINE_INDEX::get_file_properties_in_index, file_name, extensions, num_rows
compile_opt idl2
files = (*self.row_lines).file
exts = (*self.row_lines).extension
row_nums = (*self.row_lines).row_num
file_exts = exts[where(files eq file_name)]
extensions = file_exts[uniq(file_exts,sort(file_exts))]
num_rows = lonarr(n_elements(extensions))
for i=0,n_elements(extensions)-1 do begin
ind = where(files eq file_name and exts eq extensions[i], count)
num_rows[i] = count
endfor
END
;+
; Returns the center frequency using the following equation:
;
;
; center_chan = (double(num_chan)/2.0)-0.5D
; center_freq = (((center_chan - double(ref_chan))*freq_interval)+ref_freq
;
;
;
; @param ref_freq {in}{required}{type=float} reference frequency
; @param ref_chan {in}{required}{type=long} reference channel
; @param freq_interval {in}{required}{type=float} frequency interval
; @param num_chan {in}{required}{type=long} number of channels
;-
FUNCTION LINE_INDEX::get_center_frequency, ref_freq, ref_chan, freq_interval, num_chan
center_chan = (double(num_chan)/2.0)-0.5D
center_freq = ((center_chan - double(ref_chan))*freq_interval)+ref_freq
return, center_freq
END
{kind=link}
{kind=link}