;+
; Base Class used for profiling contents of sdfits files inside an ASCII file.
; File has two main sections: the header section contains generic info, while the
; rows section is a mapping of 'data containers' (spectra or continua) to their location
; in sdfits files.
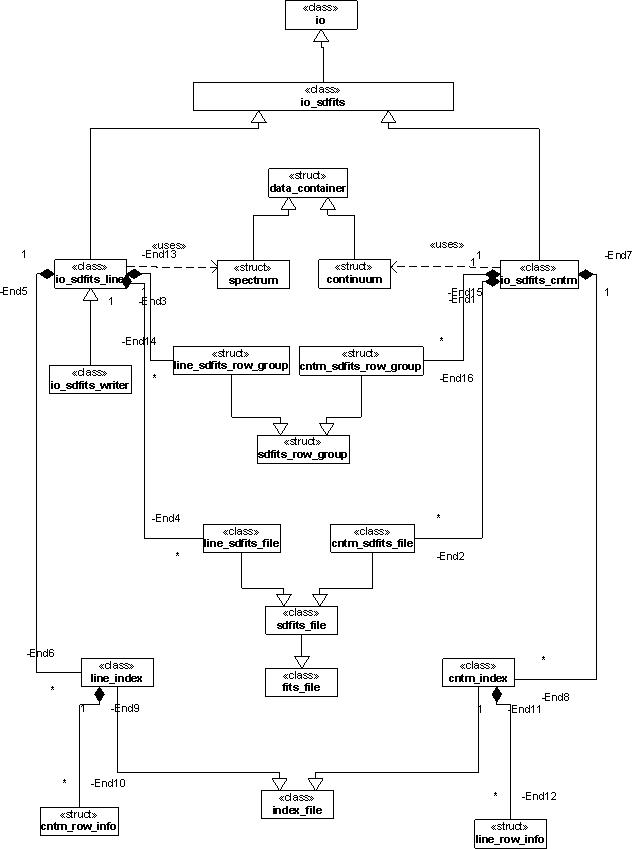
; See UML for all IO Classes,
; or INDEX UML for just index classes.
; This class is virtual: acutal index files will be handled by children of this class
; for spectral line or continuum index files. This class is responsible for:
; basic searching, file creation, modifiction gateways, basic rows translations,
; and index file verifications.
; @field file_name file name of ASCII index file.
; @field file_loaded flag that determines that this object is up to date with the index file
; @field file_path full path to the index file
; @field header object that manages the header section
; @field rows object that manages the rows section
; @field rows_class string specifiying the class used for the rows object
; @field row_lines pointer to array of structures, each representing row in index file (local copy of row object's rows).
; @field version version number passed in on class construction
; @field debug flag that determines verbosity
; @file_comments
; Base Class used for profiling contents of sdfits files inside an ASCII file.
; File has two main sections: the header section contains generic info, while the
; rows section is a mapping of 'data containers' (spectra or continua) to their location
; in sdfits files.
; See UML for all IO Classes, or
; INDEX UML for just index classes.
; This class is virtual: acutal index files will be handled by children of this class
; for spectral line or continuum index files. This class is responsible for:
; basic searching, file creation, modifiction gateways, basic rows translations,
; and index file verifications.
; @private_file
;-
PRO index_file__define
compile_opt idl2, hidden
b1 = { INDEX_FILE, $
file_name:string(replicate(32B,256)), $
file_loaded:0L, $
file_path:string(replicate(32B,256)), $
header:obj_new(), $
rows:obj_new(), $
rows_class:string(replicate(32B,256)), $
row_lines:ptr_new(), $
version:string(replicate(32B,3)), $
sprotect:0L, $
info:{file_info}, $
debug:0L $
}
END
;+
; Class Constructor - flags and constants set here.
; @keyword file_name {in}{optional}{type=string} file name of index file
; @keyword version {in}{optional}{type=string} version number
;-
FUNCTION INDEX_FILE::init, file_name=file_name, version=version
compile_opt idl2, hidden
if keyword_set(file_name) then self.file_name = file_name
if keyword_set(version) then self.version = version
self.file_loaded = 0
if keyword_set(file_name) then begin
self.header = obj_new("header_index_section", file_name)
self.rows = obj_new(self.rows_class, file_name)
endif else begin
self.header = obj_new("header_index_section")
self.rows = obj_new(self.rows_class)
endelse
self.row_lines = ptr_new()
self.sprotect = 1
self.debug = 0
return, 1
END
;+
; Class Destructor
; @private
;-
PRO INDEX_FILE::cleanup
compile_opt idl2, hidden
if obj_valid(self.header) then obj_destroy, self.header
if obj_valid(self.rows) then obj_destroy, self.rows
; self.row_lines should NOT be freed here - it is a copy of
; a pointer contained in rows_index_section
END
;+
; Sets file name of index file
; @param file_name {in}{type=string} name of index file
;-
PRO INDEX_FILE::set_file_name, file_name
compile_opt idl2
self.file_name = file_name
self.header->set_file_name, self->get_full_file_name()
self.rows->set_file_name, self->get_full_file_name()
END
;+
; Sets up object to read/create new index file
;-
PRO INDEX_FILE::reset
compile_opt idl2
if obj_valid(self.header) then obj_destroy, self.header
if obj_valid(self.rows) then obj_destroy, self.rows
if self.file_name ne "" then begin
self.header = obj_new("header_index_section", self.file_name)
self.rows = obj_new(self.rows_class, self.file_name)
endif else begin
self.header = obj_new("header_index_section")
self.rows = obj_new(self.rows_class)
endelse
self.file_loaded = 0
self.sprotect = 1
self.debug = 0
; self.row_lines should not be freed here - it is a copy of a
; pointer contained in rows_index_section
self.row_lines = ptr_new()
END
;+
; Sets path to index file
; @param file_path {in}{type=string} path to index file
;-
PRO INDEX_FILE::set_file_path, file_path
compile_opt idl2
self.file_path = file_path
self.header->set_file_name, self->get_full_file_name()
self.rows->set_file_name, self->get_full_file_name()
END
;+
; Retrieves file name of index file
; @returns file name of index file
;-
FUNCTION INDEX_FILE::get_file_name
compile_opt idl2
return, self.file_name
END
;+
; Finds if object contains index file's contents in memory
; @returns 0,1
;-
FUNCTION INDEX_FILE::is_file_loaded
compile_opt idl2
return, self.file_loaded
END
;+
; Sets version number of I/O modules
; @param version {in}{type=string} version number
;-
PRO INDEX_FILE::set_version, version
compile_opt idl2
self.version = version
END
;+
; Retrieves the version number of the I/O module using this object
; @returns version number (string)
;-
FUNCTION INDEX_FILE::get_version
compile_opt idl2
return, self.version
END
;+
; Prints the rows section of the index file for those rows specified.
; For keywords, see: ROWS_INDEX_SECTION::list
;
;-
PRO INDEX_FILE::list, _EXTRA=ex ;paz=paz, pel=pel
compile_opt idl2
if (self.file_loaded) eq 0 then begin
message, 'cannot list rows until index file is loaded. Use read_file method'
return
endif
self.rows->list, _EXTRA=ex
END
;+
; Loads contents of index file into memory. Sets file loaded flag to True.
; @keyword file_name {in}{optional}{type=string} file name of index file
; @param ver_status {out}{optional}{type=long} whether the index has
; the correct version number
; @keyword max_nrows {in}{optional}{type=integer} Maximum number of
; index rows to read - to be used for the online case only.
;-
PRO INDEX_FILE::read_file, file_name=file_name, ver_status, max_nrows=max_nrows
compile_opt idl2
; if filename is being set, we may need to recreate the section objects
if keyword_set(file_name) then begin
self->set_file_name, file_name
if obj_valid(self.header) then obj_destroy, self.header
if obj_valid(self.rows) then obj_destroy, self.rows
self.header = obj_new("header_index_section",self->get_full_file_name(self.file_name))
self.rows = obj_new(self.rows_class,self->get_full_file_name(self.file_name))
endif
; read header section
if self.header->read_file() eq -1 then message, 'error in header, cannot read.'
; make sure it's safe to attempt to read rows section
if strtrim(self.header->get_value("VERSION"),2) ne self.version then begin
ver_status = 0
return
endif else begin
ver_status = 1
endelse
; read rows section
if self.rows->read_file(max_nrows=max_nrows) eq -1 then message, 'error in rows, cannot read.'
self.row_lines = self.rows->get_rows_ptr()
; translate header values
if strtrim(self.header->get_value("SPROTECT"),2) eq '1' then self.sprotect = 1 else self.sprotect = 0
;self.file_path = strtrim(self.header->get_value("file_path"),2)
self.info = file_info(self->get_full_file_name())
self.file_loaded = 1
END
;+
; Prints contents of index header section
;-
PRO INDEX_FILE::list_header
compile_opt idl2
if self.file_loaded eq 0 then message, "file not loaded, cannot list header"
self.header->list
END
;+
; Given the search parameters used by search_index, returns the structures
; representing those rows in the index file
; @uses INDEX_FILE::search_index
; @returns array of structures representing the found rows of the index file
;-
FUNCTION INDEX_FILE::search_for_row_info, _EXTRA=ex, indicies
compile_opt idl2
if self->validate_search_keywords(ex) eq 0 then begin
print, "Error with search keywords, cannot perform search"
return, -1
endif
indicies = self->search_index(_EXTRA=ex)
if (size(indicies,/dim) eq 0) then if indicies eq -1 then return, -1
result_rows = (*self.row_lines)[indicies]
return, result_rows
END
;+
; Given the search parameters used by search_index, returns the structures
; representing the locations of each row in the index file in their sdfits files
; @uses INDEX_FILE::search_index
; @returns array of structures representing the locations of each found row
;-
FUNCTION INDEX_FILE::search_row_location, _EXTRA=ex
compile_opt idl2
indicies = self->search_index(_EXTRA=ex)
if (size(indicies,/dim) eq 0) then return, -1
location = {row_location}
result_rows = (*self.row_lines)[indicies]
for i = 0, (n_elements(indicies)-1) do begin
result_row = result_rows[i]
location.file = result_row.file
location.extension = result_row.extension
location.row_num = result_row.row_num
if (i eq 0) then locations = [location] else locations = [locations,location]
endfor
return, locations
END
;+
; Multiplexes searches according to the array type and the query type.
; @param search_arr {in}{type=array} array to be searched
; @param values {in}{type=array} array of values to be searched for in array
; @param status {out}{optional}{type=long} 1 - no problems, 0 - type error
; @uses INDEX_FILE::find_int_ranges
; @uses INDEX_FILE::find_exact_matches
; @uses INDEX_FILE::find_float_ranges
; @uses INDEX_FILE::find_string_matches
; @returns array of indicies where the values can be found in search array
; @examples
;
; >arr = [1,3,5,7]
; >values = [3,7]
; >print, index->find_values(arr,values)
; >1,3
;
; >arr = ['dog','mouse','cat','moose']
; >values = ['dog','mo*']
; >print, index->find_values(arr,values)
; >0,1,3
;
; @private
;-
FUNCTION INDEX_FILE::find_values, search_arr, values, status
compile_opt idl2
status = 0
; find the types
search_arr_type = size(search_arr,/type)
if (search_arr_type eq 3) then search_arr_type = 2
if (search_arr_type eq 5) then search_arr_type = 4
values_type = size(values,/type)
if (values_type eq 3) then values_type = 2
if (values_type eq 5) then values_type = 4
case search_arr_type of
2: begin ; ints - 2,3
case values_type of
7: begin ; string
indicies = self->find_int_ranges(search_arr, values)
end
2: begin ; ints
indicies = self->find_exact_matches(search_arr, values, total_count)
end
else: begin ; error
message, "Type of value not supported for this column: must be string range, or integer.", /info
return, -1
end
endcase
end
4: begin ; floating point - 4,5
case values_type of
4: begin
;message, "searching floats with floats not yet supported"
indicies = self->find_exact_matches(search_arr, values, total_count)
end
7: begin ; string - a range
;message, "searching floats with string ragnes not yet supported"
indicies = self->find_float_ranges(search_arr, values)
end
else: begin ; error
message, "Floating points must be searched with a float or string range", /info
return, -1
end
endcase
end
7: begin ; string
if (values_type eq 7) then begin
; ignore wildcards for now
indicies = self->find_string_matches(search_arr, values)
endif else begin
message, "Only string values are used for searching this column", /info
return, -1
endelse
end
else: begin ; error
message, "Type of column not supported for searches", /info
return, -1
end
endcase
status = 1
return, indicies
END
;+
; Queries the input array with an array of canidates, and allows for wildcards ('*') at
; the begining and end of canidate strings.
; @param array {in}{type=array} array to be searched
; @param values {in}{type=array} array of values to be searched for in array
; @returns array of indicies where the values can be found in search array
; @examples
;
; >arr = ['dog','mouse','cat','moose']
; >values = ['dog','mo*']
; >print, index->find_string_matches(arr,values)
; >0,1,3
;
; @private
;-
FUNCTION INDEX_FILE::find_string_matches, array, values
compile_opt idl2
if (size(values,/type) ne 7) then message, "values param must be of type string"
; init final result
final_result = [-1]
; go through each value, ANDing results
for i=0,n_elements(values)-1 do begin
value = values[i]
value = strtrim(value,2)
count = 0
; look for a wildcard
wildcard_pos = strpos(value,'*')
case wildcard_pos of
0: begin ; wildcard at begining
; we are now only looking for string that match with the last n chars
search_value = strmid(value,1)
l = strlen(search_value)
search_array = strarr(n_elements(array))
for j=0,n_elements(array)-1 do begin
search_array[j] = strmid(array[j],l-1,l,/reverse_offset)
endfor
result = where(search_array eq search_value, count)
end
strlen(value)-1: begin ; wildcard at end
; we are now only looking for string that match with the first n chars
search_value = strmid(value,0,strlen(value)-1)
l = strlen(search_value)
search_array = strarr(n_elements(array))
for j=0,n_elements(array)-1 do begin
search_array[j] = strmid(array[j],0,l)
endfor
result = where(search_array eq search_value, count)
end
-1: begin ; no wildcard
result = self->find_exact_matches(array, value, count)
end
endcase
; append these results
if (count ne 0) then final_result = [final_result,result]
endfor
; get rid of init value
if (n_elements(final_result) gt 1) then final_result=final_result[1:n_elements(final_result)-1]
; collapse any reduntand results from overlapping ranges
final_result = final_result[sort(final_result)]
final_result = final_result[uniq(final_result)]
return, final_result
return, indicies
END
;+
; Queries the input array with an array of canidates, where canidates can be a
; string representing a single float, or a range of the form: '0.0:1.0' or ':0.0',
; or '0.0:'
; Warning: double quotes ("") don't work with ranges - use single quotes ('')
; @param array {in}{type=array} array of floats to be searched
; @param values {in}{type=string} string representing range to be searched for in array
; @returns array of indicies where the values can be found in search array
; @examples
;
; >arr = [0.0,0.5,1.0,1.5,2.0,2.5,3.0,3.5,4.0]
; >values = ':1.0,2.5:4.0'
; >print, index->find_string_matches(arr,values)
; >0,1,6,7
;
; @private
;-
FUNCTION INDEX_FILE::find_float_ranges, array, values
compile_opt idl2
if (size(values,/type) ne 7) then message, "values param must be of type string"
; init final result
final_result = [-1]
; get rid of leading and trailing whitespace
values = strtrim(values,2)
; go through each range, ANDing results
ranges = strsplit(values,",",/extract)
for i=0,n_elements(ranges)-1 do begin
range = ranges[i]
; determine the type of range, and find results
colon_pos = strpos(range,":")
count = 0
case colon_pos of
0: begin ; less then
limit = double(strmid(range,1,strlen(range)-1))
result = where(array le limit,count)
end
strlen(range)-1: begin ; greater then
limit = double(strmid(range,0,strlen(range)-1))
result = where(array ge limit,count)
end
-1: begin ; simple float - treat like a small range
; watch for any exponent
range = strlowcase(range)
; exponent begins with e or d
ePos = strpos(range,'e')
expValue = 1.d
if ePos ge 0 then begin
expStr = strmid(range,ePos)
expValue = double('1.0'+expStr)
endif else begin
ePos = strpos(range,'d')
if ePos ge 0 then begin
expStr = strmid(range,ePos)
expValue = double('1.0'+expStr)
endif
endelse
if ePos eq 0 then begin
range = '1'
endif else begin
if ePos gt 0 then begin
range = strmid(range,0,ePos)
endif
endelse
parts = strsplit(range,'.',/extract)
base_range = double(range)*expValue
if (n_elements(parts) eq 1) then begin
offset = 0.5
endif else begin
precision = strlen(parts[1])
offset = 5.0/(10.d^(precision+1))
endelse
offset = offset*expValue
low_limit = base_range - offset
up_limit = base_range + offset
result = where((array ge low_limit) and (array le up_limit),count)
end
else: begin ; range
limits = strsplit(range,":",/extract)
low_limit = double(limits[0])
up_limit = double(limits[1])
result = where((array ge low_limit) and (array le up_limit),count)
end
endcase
; append these results
if (count ne 0) then final_result = [final_result,result]
endfor
; get rid of init value
if (n_elements(final_result) gt 1) then final_result=final_result[1:n_elements(final_result)-1]
; collapse any reduntand results from overlapping ranges
final_result = final_result[uniq(final_result)]
return, final_result
END
;+
; A wrapper around a 'where' so that the locations of several values can be found in an array
; @param search_arr {in}{type=array} array to be searched
; @param values {in}{type=array} array of values to be searched for in array
; @returns array of indicies where the values can be found in search array
; @private
;-
FUNCTION INDEX_FILE::find_exact_matches, search_arr, values, total_count
compile_opt idl2
total_count = 0
count = 0
for i=0, (n_elements(values)-1) do begin
value = values[i]
temp_inds = where(search_arr eq value, count)
if (count ne 0) then begin
if (total_count eq 0) then indicies = temp_inds else indicies = [indicies,temp_inds]
total_count = total_count + count
endif
endfor
if (total_count eq 0) then indicies = -1
return, indicies
END
;+
; Queries the input array with an array of canidates, where canidates must be a
; string representing a range of integers of the form: '0:10' or ':0',
; or '0:'
; Warning: double quotes ("") don't work with ranges - use single quotes ('')
; @param array {in}{type=array} array of ints to be searched
; @param values {in}{type=string} string representing range to be searched for in array
; @returns array of indicies where the values can be found in search array
; @examples
;
; >arr = [0,5,10,15,20,25,30,35,40]
; >values = ':10,25:40'
; >print, index->find_string_matches(arr,values)
; >0,1,6,7
;
; @private
;-
FUNCTION INDEX_FILE::find_int_ranges, array, values
compile_opt idl2
if (size(values,/type) ne 7) then message, "values param must be of type string"
; init final result
final_result = [-1L]
; get rid of leading and trailing whitespace
values = strtrim(values,2)
; go through each range, ANDing results
ranges = strsplit(values,",",/extract)
for i=0,n_elements(ranges)-1 do begin
range = ranges[i]
; determine the type of range, and find results
colon_pos = strpos(range,":")
count = 0
case colon_pos of
0: begin ; less then
limit = long(strmid(range,1,strlen(range)-1))
result = where(array le limit,count)
end
strlen(range)-1: begin ; greater then
limit = long(strmid(range,0,strlen(range)-1))
result = where(array ge limit,count)
end
-1: begin ; simple integer
limit = long(range)
result = where((array eq limit), count)
end
else: begin ; range
limits = strsplit(range,":",/extract)
low_limit = long(limits[0])
up_limit = long(limits[1])
result = where((array ge limits[0]) and (array le limits[1]),count)
end
endcase
; append these results
if (count ne 0) then final_result = [final_result,result]
endfor
; get rid of init value
if (n_elements(final_result) gt 1) then final_result=final_result[1:n_elements(final_result)-1]
; collapse any reduntand results from overlapping ranges
final_result = final_result[uniq(final_result)]
return, final_result
END
;-
; Used in searching the index record. Searches the input array for
; matches to the given values argument. Returns the list of matching
; index values from the arr_index vector, which is the original index
; locations of the array being searched. That returned value can then
; be used to refine the search using other parameters.
;
; @param arr {in}{required}{type=array} The input array to search.
; @param values {in}{required} The values to search in arr. Following
; the syntax used in the various fields in search_index.
; @param arr_index {in}{required}{type=int array} The original index
; locations corresponding to arr. Assumed to have same length as arr.
; @param name {in}{required}{type=string} The name of the field
; in the index record that arr coresponds to. Used in error
; reporting.
; @param Count {out}{required}{type=integer} Set to number of elements
; found. This is set to 0 when nothing has been found (and return
; value is -1).
; @returns The arr_index values corresponding to the arr locations
; that match the set of values. Returns -1 if no matches were found.
;-
FUNCTION INDEX_FILE::refine_search, arr, values, arr_index, name, count
compile_opt idl2
count = 0
if n_elements(arr_index) eq 1 then begin
if arr_index eq -1 then return, arr_index
endif
index_found = self->find_values(arr, values, status)
; if there was a problem with this search (wrong type), inform
; the user that this search will be ignored
if status eq 0 then begin
message, "search on column to be ignored: "+name, /info
return, arr_index
endif
if n_elements(index_found) eq 1 then begin
if index_found eq -1 then begin
return, -1
endif
endif
count = n_elements(index_found)
return, arr_index[index_found]
END
;+
; Used for making a search in an array and ANDing the results with previous searches
; @uses INDEX_FILE::find_values
; @examples
;
; >a = [1,2,3,4]
; >b = ['dog','cat','mouse','moose']
; >;init the search results
; >and_result = [0,1,2,3]
; >io->find_values_plus_and,a,'1:',and_result
; >print,and_result
; >[1,2,3]
; >io->find_values_plus_and,b,'dog,mo*',and_result
; >print,and_result
; >[2,3]
;
; @private
;-
PRO INDEX_FILE::find_values_plus_and, array, values, and_result, name
compile_opt idl2
if n_elements(and_result) eq 1 then begin
if and_result eq -1 then return
endif
values_result = self->find_values(array[and_result], values, status)
; if there was a problem with this search (wrong type), inform the user
; that this search will be ignored
if status eq 0 then begin
message, "Search on column to be ignored: "+name, /info
return
endif
if n_elements(values_result) eq 1 then begin
if values_result eq -1 then begin
and_result = -1
endif else begin
and_result = and_result[values_result]
endelse
endif else begin
and_result = and_result[values_result]
endelse
END
;+
; Creates a new index file, initializing the header section
; @param observer {in}{type=string} observer
; @param backend {in}{type=string} backends used in the listed observations
; @param tcal_table {in}{type=string} table used for tcal values (not currently implemented)
; @param file_path {in}{type=string} path where all sdfits files can be found
; @keyword file_name {in}{optional}{type=string} name of index file can be specified here
; @uses INDEX_FILE::set_file_name
; @uses INDEX_FILE::new_header_string
; @uses INDEX_FILE::write_index_file
;-
PRO INDEX_FILE::new_file, observer, backend, tcal_table, file_path, file_name=file_name
compile_opt idl2
if keyword_set(file_name) then self->set_file_name, file_name
self.file_path = file_path
; writes over any pre-existing files
openw, lun, self->get_full_file_name(), /get_lun
free_lun, lun
; write the header section
header_string = self->new_header_string(observer, backend, tcal_table, file_path)
self->write_index_file, header_string
self.file_loaded = 1
END
;+
; Creates a string array of key-value pairs from the input info; used to create the header section
; @param observer {in}{type=string} observer
; @param backend {in}{type=string} backends used in the listed observations
; @param tcal_table {in}{type=string} table used for tcal values (not currently implemented)
; @param file_path {in}{type=string} path where all sdfits files can be found
; @returns string array of key-value pairs from input params.
; @private
;-
FUNCTION INDEX_FILE::new_header_string,observer,backend,tcal_table,file_path
compile_opt idl2
creation_date = systime(/UTC)
header = ['created = '+creation_date]
header = [header,'last_modified = '+creation_date]
header = [header,'version = '+self.version]
header = [header,'observer = '+observer]
header = [header,'backend = '+backend ]
header = [header,'tcal_rx_table = '+tcal_table ]
;header = [header,'file_path = '+file_path ]
header = [header,'created_by = gbtidl']
header = [header,'sprotect = '+strtrim(string(self.sprotect),2) ]
return, header
END
;+
; Retrieves values found for a column in the index file (all the files for exampler).
; @param column {in}{type=string} name of column to query, must match a column name form index
; @keyword unique {in}{optional}{type=boolean} just return the unique values for this column?
; @keyword subset {in}{optional}{type=array} array of integers which index the position of the rows in the index file; supercedes any search keywords passed. If set, only values from this subset are returned
; @uses INDEX_FILE::get_row_info_strct
; @returns the values found for a column in the index file
;-
FUNCTION INDEX_FILE::get_column_values, column, unique=unique, subset=subset, _EXTRA=ex
compile_opt idl2
column = strupcase(column)
; what rows in the index file are we querying?
index_rows = self->search_index(_EXTRA=ex)
if (size(index_rows,/dim) eq 0) then if index_rows eq -1 then return, -1
; if subset param used, this supercedes any searching doe
if n_elements(subset) ne 0 then begin
index_rows = subset
endif
column_names = self.rows->get_available_columns()
cnt = 0
ind = where(column eq column_names,cnt)
if cnt eq 0 then begin
message, "Column name not valid: "+column, /info
return, -1
endif
values = (*self.row_lines).(ind)
; return only the values which are the subset from the search
values = values[index_rows]
if keyword_set(unique) then begin
sorted_values = values[sort(values)]
values = sorted_values[uniq(sorted_values)]
endif
return, values
END
;+
; Takes a given header section and list of rows, and writes them to a file
; @param header_strings {in}{type=array} string array of key-value pairs for header section
; @keyword rows_info {in}{optional}{type=array} array of structures representing rows for index file
;-
pro INDEX_FILE::write_index_file, header_strings, rows_info=rows_info
compile_opt idl2
self.header->set_file_name, self->get_full_file_name()
self.header->create, header_strings
self.rows->create
return
end
;+
; Appends new rows to the end of the rows section of index file
; @param rows_info {in}{type=array} array of structures representing rows to be appended
;-
PRO INDEX_FILE::update_index_file, rows_info
compile_opt idl2
self.rows->write_rows, rows_info
if self.header->set_value("last_modified",systime(/UTC)) eq -1 then begin
message, "Could not set header keyword last_modiifed"
endif
self.row_lines = self.rows->get_rows_ptr()
END
;+
; Overwrites a row in the index file with a different row structure
; @param index_num {in}{required}{type=long} index number of row which is to be overwritten
; @param new_row {in}{required}{type=struct} new row to write in index file at index_num
;-
PRO INDEX_FILE::overwrite_row, index_num, new_row
compile_opt idl2
self.rows->overwrite_row, index_num, new_row
self.row_lines = self.rows->get_rows_ptr()
END
;+
; Extracts procedure name from sdfits OBSMODE column
; @param obsmode {in}{type=string} OBSMODE column value from sdfits file
; @returns procedure name
; @private
;-
function INDEX_FILE::get_procedure_from_obsmode, obsmode
compile_opt idl2
obsmodes = strsplit(obsmode,":",/extract)
return, obsmodes[0]
end
;+
; Translates sdfits value of polarizaiton to a char representation
; @param polarization {in}{type=long} sdfits representation of polarization
; @returns polarization in char representation
; @private
;-
function INDEX_FILE::translate_polarization, polarization
compile_opt idl2
case polarization of
1: value = 'I'
2: value = 'Q'
3: value = 'U'
4: value = 'V'
-1: value = 'RR'
-2: value = 'LL'
-3: value = 'RL'
-4: value = 'LR'
-5: value = 'XX'
-6: value = 'YY'
-7: value = 'XY'
-8: value = 'YX'
else: value = '?'
endcase
return, value
END
;+
; Given rows from an sdfits file, how much does the value of a given column vary?
; Used when translating contents of an sdfits file into contents of the index file.
; @param rows {in}{type=array} array of structures mirroring sdfits rows
; @param tag_name {in}{type=string} column in the sdfits rows we are querying
; @param names {in}{type=struct} structure containing pointers to the list of row columns, missing cols, and header keywords
; @param default_value {in} if the tag_name is not found in the rows or as a keyword, use this as the variability
; @returns the variablity of this column in the fits file
; @private
;-
FUNCTION INDEX_FILE::get_col_variability, rows, tag_name, names, default_value
compile_opt idl2
variability = 1
i = where(tag_name eq *names.row)
if (i ne -1) then begin
; its in the sdfits row
values = rows.(i)
sorted = values[sort(values)]
uniques = sorted[uniq(sorted)]
variability = n_elements(uniques)
endif else begin
i = where(tag_name eq *names.virtuals)
if (i ne -1) then begin
; its a keyword in ext header
variability = 1
endif else begin
; see if there are missing cols to check
if (size(*names.missing,/dim) ne 0) then begin
i = where(tag_name eq *names.missing)
endif else begin
i = -1
endelse
if (i ne -1) then begin
; its a missing column from sdfits row; ex: CAL
variability = default_value
endif else begin
; fits no case
variability = 1
endelse
endelse
endelse
return, variability
END
;+
; Algorithm for determining polarization numbers (0-based), given the sdfits rows of a scan.
; @param scan_rows {in}{type=array} array of sdfits rows for just one scan
; @param names {in}{type=struct} structure containing pointers to names of sdfits columns, missing columns, and keywords
; @returns an array for polarization numbers of each row in index file for this scan (ex: [0,0,1,1,0,0,1,1,...])
; @uses INDEX_FILE::get_col_variability
; @private
;-
FUNCTION INDEX_FILE::get_polarization_numbers, scan_rows, names
compile_opt idl2
; how many different polarizations are there?
n_pols = self->get_col_variability(scan_rows,'CRVAL4',names,1)
n_rows = n_elements(scan_rows)
if n_pols eq 1 then begin
; either there is just one FEED value used, or FEED column is absent:
; beam numbers are all zeros
pol_nums = lonarr(n_rows)
endif else begin
; we can assume that the polarizations column is included
pols = scan_rows.crval4
u_pols = pols[uniq(pols, sort(pols))]
pol_nums = lonarr(n_rows)
for i=0,n_elements(u_pols)-1 do begin
j = where(pols eq u_pols[i])
pol_nums[j] = i
endfor
endelse
return, pol_nums
END
;+
; Method for attempting to extract a value from an sdfits row. If the row contains the
; tag name requested, that value is passed back. If that tag name actually specifies a
; keyword in the extension-header, and NOT a column, then that value is returned. Finally,
; if the tag name mathes one of the expected column names that were not found in this
; extension, the default value is returned.
; @param row {in}{type=struct} structure that mirrors a row in an sdfits file
; @param tag_name {in}{type=string} name of the value that we want to retrieve
; @param virtuals {in}{type=struct} struct giving the keyword-values found in the file-extension
; @param names {in}{type=struct} struct contiaining pointers to the names of columns in the row, missing columns, and tag names in the virtuals struct
; @param default_value {in} value to be returned if the tag_name is of a missing column
; @returns either the value of row.tag_name, virtauls.tag_name, or default_value
; @private
;-
FUNCTION INDEX_FILE::get_row_value, row, tag_name, virtuals, names, default_value
compile_opt idl2
; look for the tag name inside each member of 'names'
i = where(tag_name eq *names.row)
if (i ne -1) then begin
; its in the sdfits row
value = row.(i)
endif else begin
i = where(tag_name eq *names.virtuals)
if (i ne -1) then begin
; its a keyword in ext header
value = virtuals.(i)
endif else begin
; see if there are missing cols to check
if (size(*names.missing,/dim) ne 0) then begin
i = where(tag_name eq *names.missing)
endif else begin
i = -1
endelse
if (i ne -1) then begin
; its a missing column from sdfits row
value = default_value ;missing.(i)
endif else begin
; use the default value again
;print, 'tag_name: '+tag_name+' not found in row, missing, or virtuals'
value = default_value
endelse
endelse
endelse
return, value
END
;+
; If this object is using the file path, returns full path name of index file
; @private
;-
FUNCTION INDEX_FILE::get_full_file_name, file_name
compile_opt idl2
if (keyword_set(file_name) eq 0) then file_name = self.file_name
if (self.file_path eq '') then begin
full_file_name = file_name
endif else begin
full_file_name = self.file_path + '/' + file_name
endelse
return, full_file_name
END
;+
; Checks the contents of the index file with the actual charcteristics of the files it lists, looking for inconsistencies
; @param expanded {in}{optional}{type=boolean} is it allowable that an sdfits file has grown since this index file was created?
; @keyword verbose {in}{optional}{type=boolean} print details of all errors?
; @uses INDEX_FILE::get_full_file_name
; @uses INDEX_FILE::check_io_version_number
; @uses INDEX_FILE::is_file_loaded
; @uses INDEX_FILE::file_exists
; @uses INDEX_FILE::check_file_properties
; @returns 0,1
;-
FUNCTION INDEX_FILE::check_index_with_reality, expanded, verbose=verbose
compile_opt idl2
if (n_params() eq 1) then checking_expansion = 1 else checking_expansion = 0
if checking_expansion then expanded = 0
if keyword_set(verbose) then loud = 1 else loud = 0
congruent = 0
; is file loaded?
if (self->is_file_loaded() eq 0) then begin
message, 'Cannot check index file until it is loaded'
return, 0
endif
; check io version number
if (self->check_io_version_number() eq 0) then begin
if loud then print, 'index file made with old I/O version number; delete this file to create a new one'
return, 0
endif
; get all files listed in index file
files = (*self.row_lines).file
files = files[uniq(files,sort(files))]
; do all files in index exist in reality
for i=0,n_elements(files)-1 do begin
if (self->file_exists(file_name=self->get_full_file_name(files[i])) eq 0) then begin
if loud then print, 'index does not match reality; file not found: '+self->get_full_file_name(files[i])
return, 0
endif
endfor
; for each file, check extensions and ext. sizes
for i=0,n_elements(files)-1 do begin
if checking_expansion then begin
congruent = self->check_file_properties(files[i],expanded,/verbose)
endif else begin
congruent = self->check_file_properties(files[i],/verbose)
endelse
if (congruent eq 0) then return, 0
endfor
; return success
return, 1
END
;+
; Compares io version number found in index file with number coded in object
; @uses INDEX_FILE::get_header_value
; @returns 0,1
;-
FUNCTION INDEX_FILE::check_io_version_number
compile_opt idl2
; cant do anything if we haven't read in the file already
if (self.file_loaded eq 0) then message, "cannot check io version number until file is loaded"
; check that the version tag exists
version = self.header->get_value("version")
if (version eq -1) then return, 0
; does the value for the version tag match the current version?
if (version eq self.version) then return, 1 else return, 0
END
;+
; Checks if file exists
; @keyword file_name {in}{optional}{type=string} file to check
; @returns 0,1
; @private
;-
FUNCTION INDEX_FILE::file_exists, file_name=file_name
compile_opt idl2
if keyword_set(file_name) then begin
file_info = file_info(file_name)
endif else begin
if (self.file_path eq '') then begin
file_info = file_info(self.file_name)
endif else begin
file_info = file_info(self.file_path+'/'+self.file_name)
endelse
endelse
return, file_info.exists
END
;+
; If the start and finish parameters are used, it pares down the search indicies to just
; cover the range requested.
; @param start {in}{optional}{type=long} where range starts (1-based)
; @param finish {in}{optional}{type=long} where range ends
; @param search_result {in}{required}{type=array} the indicies that show the current state of the search
; @returns long array which is the result of the range on the search
; @private
;-
FUNCTION INDEX_FILE::search_range, start, finish, search_result
compile_opt idl2
; if the start and finish parameters have been passed, act as if this is the INDEX keyword
if (n_elements(start) ne 0) and (n_elements(finish) ne 0) then begin
if (start gt finish) then message, "start index: "+string(start)+" must be less then ending index: "+string(finish)
if (start lt 0) then message, "start index must be greater then or equal to zero"
if (finish ge self->get_num_index_rows()) then message, "ending index must be less then number of indicies: "+string(self->get_num_index_rows())
search_result = where((*self.row_lines).index ge start and (*self.row_lines).index le finish)
endif
return, search_result
end
;+
; Sorts and uniques an array
; @param arr {in}{type=array} array to be sorted and uniqued
; @returns uniqe values of array
; @private
;-
FUNCTION INDEX_FILE::get_uniques, arr
compile_opt idl2
return, arr[uniq(arr,sort(arr))]
END
;+
; Makes object verbose
;-
PRO INDEX_FILE::set_debug_on
compile_opt idl2
self.debug = 1
if obj_valid(self.header) then self.header->set_debug_on
if obj_valid(self.rows) then self.rows->set_debug_on
END
;+
; Makes object quiet
;-
PRO INDEX_FILE::set_debug_off
compile_opt idl2
self.debug = 0
if obj_valid(self.header) then self.header->set_debug_off
if obj_valid(self.rows) then self.rows->set_debug_off
END
;+
; Checks basic file properties to see if they agree with what the index file has listed.
; @param file_name {in}{type=string} sdfits file to check
; @param expanded {in}{optional}{type=boolean} has this file been expanded since its listing in the index file?
; @keyword verbose {in}{optional}{type=boolean} print out details of errors?
; @returns 0,1
; @private
;-
FUNCTION INDEX_FILE::check_file_properties, file_name, expanded, verbose=verbose
compile_opt idl2
if (n_params() eq 2) then checking_expansion = 1 else checking_expansion = 0
if checking_expansion then expanded = 0
if keyword_set(verbose) then loud =1 else loud = 0
; get the number of extensions and rows/ext. according to the index file
self->get_file_properties_in_index, file_name, index_exts, index_rows
; open this fits file and get same properties
fits = obj_new('fits',self->get_full_file_name(file_name))
file_exts = lindgen(fits->get_number_extensions())+1
file_rows = make_array(n_elements(file_exts),value=0L)
for i=0,n_elements(file_rows)-1 do begin
file_rows[i] = fits->get_ext_num_rows(file_exts[i])
endfor
obj_destroy, fits
; ignore any zero-row extensions
nonZeroExts = where(file_rows ne 0,count)
if count ne n_elements(file_rows) then begin
if count eq 0 then begin
; everything has zero rows, should not happen
message,'FITS file is empty - no table rows, can not continue'
endif else begin
; exclude those rows
file_rows = file_rows[nonZeroExts]
file_exts = file_exts[nonZeroExts]
endelse
endif
; check number of extensions
if (n_elements(index_exts) ne n_elements(file_exts)) then begin
; if the file has more extensions then index, it may have been expanded
if (n_elements(index_exts) lt n_elements(file_exts)) and checking_expansion then expanded = 1
if loud then print, 'file: '+file_name+' does not have same number of extensions as index reports'
return, 0
endif
; for each extension, how many rows does it have
for i=0,n_elements(file_rows)-1 do begin
if (file_rows[i] ne index_rows[i]) then begin
; not congruent, but has the file been expanded?
if (file_rows[i] gt index_rows[i]) and (i eq n_elements(file_rows)-1) and (checking_expansion eq 1) then expanded = 1
if loud then print, 'file: '+file_name+', ext: '+string(i)+' does not have same number of rows as index reports'
return, 0
endif
endfor
; file properties match index
return, 1
END
;+
; Retrieves the unique index number for a given unique nsave number.
;
; @param nsave {in}{required}{type=long} unique integer id number in nsave column
;
; @returns the unique index number for the row where this nsave number is found
;
;-
FUNCTION INDEX_FILE::get_nsave_index, nsave
compile_opt idl2, hidden
; its possible that this is being called before an index file has been created
if self->is_file_loaded() eq 0 then return, -1
; do a simple search using this nsave number.
nsave_row_info = self->search_for_row_info(nsave=nsave)
; did we find just one row?
if n_elements(nsave_line_location) gt 1 then message, "nsave number not unique in index file: "+string(nsave)
if size(nsave_row_info,/type) ne 8 then begin
return, -1
endif else begin
return, nsave_row_info.index
endelse
END
;+
; Sets the nsave number for a given index number in the index file
;
; @param index_num {in}{required}{type=long} the index number for which we are setting the nsave number
; @param nsave {in}{required}{type=long} the nsave number to be written to the index file
;
;-
PRO INDEX_FILE::set_nsave, index_num, nsave
compile_opt idl2, hidden
self.rows->overwrite_row_column, index_num, "NSAVE", nsave
self.row_lines = self.rows->get_rows_ptr()
END
;+
; Sets index file so nsave numbers cannot be overwritten
;-
PRO INDEX_FILE::set_sprotect_on
compile_opt idl2, hidden
if self->is_file_loaded() then begin
; set both index file value and value in memory
if self.header->set_value("SPROTECT", '1') eq -1 then message, "Could not set sprotect"
endif
self.sprotect = 1
END
;+
; Sets index file so nsave numbers can be overwritten
;-
PRO INDEX_FILE::set_sprotect_off
compile_opt idl2, hidden
if self->is_file_loaded() then begin
; set both index file value and value in memory
if self.header->set_value("SPROTECT", '0') eq -1 then message, "Could not set sprotect"
endif
self.sprotect = 0
END
;+
; Retrieves the state of nsave protection
; @returns 0 - nsave numbers cannot be overwritten; 1 - they cannot be overwritten
;-
FUNCTION INDEX_FILE::get_sprotect
compile_opt idl2, hidden
return, self.sprotect
END
;+
; Diagnostic function to determine if index file indicies are unique (as they should be)
; @returns 0 - bad, 1 - good
;-
FUNCTION INDEX_FILE::are_index_file_indicies_unique
compile_opt idl2, hidden
all_indicies = self->get_column_values("INDEX")
unique_indicies = self->get_column_values("INDEX",/unique)
if n_elements(all_indicies) ne n_elements(unique_indicies) then begin
message, "all indicies vs. uniques: "+string(n_elements(all_indicies))+string(n_elements(unique_indicies)), /info
return, 0
endif else begin
return, 1
endelse
END
;+
; Sets the object to print rows using the interactive 'more' format
;-
PRO INDEX_FILE::set_more_format_on
compile_opt idl2, hidden
self.rows->set_more_format_on
END
;+
; Sets the object NOT to print rows using the interactive 'more' format
;-
PRO INDEX_FILE::set_more_format_off
compile_opt idl2, hidden
self.rows->set_more_format_off
END
;+
; Prints the available columns from the rows section for list;
; these are also the valid search keywords
;-
PRO INDEX_FILE::list_available_columns
compile_opt idl2, hidden
self.rows->list_available_columns
END
;+
; Sets what columns should be used for user listing
; @param columns {in}{required}{type=string array} array of columns to print on list command
;-
PRO INDEX_FILE::set_user_columns, columns
compile_opt idl2, hidden
self.rows->set_user_columns, columns
END
;+
; Prints the columns currently selected for the user specified listing
;-
PRO INDEX_FILE::list_user_columns
compile_opt idl2, hidden
self.rows->list_user_columns
END
;+
; Returns the available columns from the rows section for list;
; these are also the valid search keywords
;-
FUNCTION INDEX_FILE::get_available_columns
compile_opt idl2, hidden
return, self.rows->get_available_columns()
END
FUNCTION INDEX_FILE::get_param_types
compile_opt idl2, hidden
return, self.rows->get_param_types()
END
;+
; For reading into memory the new rows that may have been written to the
; index file ( by hand, or by an online process ). First checks file size to
; see if there might be any new lines, then jumps to previous last line, and
; reads new rows.
; @param num_new_lines {out}{optional}{type=long} number of new rows
; found in index file
; @keyword max_nrows {in}{optional}{type=long} maximum number of total
; rows to read (new rows + old rows <= max_nrows)
;-
PRO INDEX_FILE::read_new_rows, num_new_lines, max_nrows = max_nrows
compile_opt idl2, hidden
; assumes header has no new lines, just new row lines
self.rows->read_new_rows, num_new_lines, max_nrows=max_nrows
self.row_lines = self.rows->get_rows_ptr()
END
;+
; Retrieve the structure that has info on the index file - updated only on reading file, or
; read_new_rows
; @returns a {file_info} structure
;-
FUNCTION INDEX_FILE::get_info
compile_opt idl2
return, self.info
END
;+
; Sets the structure that has info on the index file
; @param info {in}{required}{type=file_inf} a {file_info} structure
;-
PRO INDEX_FILE::set_info, info
compile_opt idl2
self.info = info
END
;+
; Takes in an _EXTRA structure, and validates tags according to the columns listed in the format.
; @returns 0 - invalid, 1 - valid
;-
FUNCTION INDEX_FILE::validate_search_keywords, keyword_struct
compile_opt idl2
if n_elements(keyword_struct) eq 0 then return, 1
if size(keyword_struct,/type) ne 8 then begin
message, "_EXTRA is not a structure: cannot validate search keywords", /info
return, -1
endif
; what are the keywords in the sturcture
keywords = tag_names(keyword_struct)
; what are the keywords allowed? + UNIQUE, SROW, NROW
searchkeys = [self->get_available_columns(),"UNIQUE","SROW","NROW"]
; keep track of what is not an exact match
keys_match = lonarr(n_elements(keywords))
for i=0,n_elements(keywords)-1 do begin
cnt = 0
ind = where(keywords[i] eq searchkeys,cnt)
if cnt eq 1 then keys_match[i]=1 else keys_match[i]=0
endfor
; for all the non-exact matches, is it unambigious?
keys_result = lonarr(n_elements(keywords))+1L
for i=0,n_elements(keywords)-1 do begin
if keys_match[i] ne 1 then begin
key = keywords[i]
key_len = strlen(key)
; create an array of the searchkeys of this length
shortsearch = strmid(searchkeys,0,key_len)
cnt = 0
ind = where(key eq shortsearch, cnt)
if cnt ne 1 then begin
if cnt eq 0 then begin
print, "bad keyword: "+key
endif else begin
print, "ambigious key "+key+" matches: "
print, searchkeys[ind]
endelse
endif
keys_result[i] = cnt
endif
endfor
cnt = 0
ind = where(keys_result ne 1, cnt)
if cnt ne 0 then begin
return, 0
endif else begin
return, 1
endelse
END
;+
; Retrieves the number of rows currently in index file
; @returns number of rows in index file
;-
FUNCTION INDEX_FILE::get_num_index_rows
compile_opt idl2
return,(ptr_valid(self.row_lines) ? n_elements(*self.row_lines):0)
END
;+
; Checks to make sure that all the column names submitted are valid.
; Unlike search keywords, must be an exact match, though not case sensitive
; @param columns {in}{required}{type=array} string array of column names
; @returns 0 - not valid, 1 - valid
;-
FUNCTION INDEX_FILE::validate_column_names, columns
compile_opt idl2
valid_columns = self.rows->get_available_columns()
for i=0, n_elements(columns)-1 do begin
cnt = 0
ind = where(strupcase(columns[i]) eq valid_columns, cnt)
if cnt ne 1 then begin
print, strupcase(columns[i])+" not in list of valid column names. Use LISTCOLS to see the valid names."
return, 0
endif
endfor
return, 1
END
;+
; Determines number of channels from the dimensions keyword value (TDIM#)
; This is the first number in the string: '(1,1,1,1)'
;
; @returns an integer, the first number in the string '(1,1,1,1)'
;-
FUNCTION INDEX_FILE::get_num_chans_from_dims, dimensions
compile_opt idl2
; dimensions should have format: (1,1,1,1)
parts = strsplit(dimensions,',',/extract)
return, long(strmid(parts[0],1,strlen(parts[0])))
END
;+
; Returns the array of structures representing the lines in the rows sections
; @returns array of structures
;-
FUNCTION INDEX_FILE::get_row_structs
compile_opt idl2
return, *self.row_lines
END
;+
; Instead of parsing the rows from an sdfits table, and using that info to update
; the index file, this takes in rows from another index object, changes the index
; numbers for those rows, and appends them to this objects index file
; @param row_structs {in}{required}{type=array} array of structures, returned from index object's get_row_structs()
; @returns 0 - failure, 1 - success
;-
FUNCTION INDEX_FILE::update_file_with_row_structs, row_structs
compile_opt idl2
; we must update the index file numbers in the passed in structures
if self->get_num_index_rows() ne 0 then begin
present_indicies = (*self.row_lines).index
max_index = max(present_indicies)
row_structs.index = lindgen(n_elements(row_structs))+max_index+1
endif else begin
row_structs.index = lindgen(n_elements(row_structs))
endelse
; add these lines to the index file rows section
self->update_index_file, row_structs
return, 1
END
FUNCTION INDEX_FILE::get_base_index_for_file, filename
compile_opt idl2, hidden
rows_for_file = self->search_for_row_info(file=filename)
return, rows_for_file[0].index
END
;+
; Find the longest string with a trailing wildcard that matches all
; of the filenames in the input string array. Returns "*" if there are
; no characters in common. This assumes that these are fits files and
; hence all should end in ".fits". Used in get_scan_info in the
; derived classes for the case where there are multiple FITS files
; in use.
; @param files {in}{required}{type=string array} array of file names
; @returns string guaranteed to match all elements of files
;-
FUNCTION INDEX_FILE::file_match, files
compile_opt idl2
uniqueFiles = self->get_uniques(files)
result = uniqueFiles[0]
if n_elements(uniqueFiles) gt 1 then begin
; find where the files all share the same characters
; start before .fits on the end which they should all share
commonCount = min(strpos(uniqueFiles,'.fits'))
while commonCount gt 0 do begin
matchFound = 1
for sindx=1,(n_elements(uniqueFiles)-1) do begin
if strcmp(result,uniqueFiles[sindx],commonCount) le 0 then begin
commonCount = commonCount - 1
matchFound = 0
break
endif
endfor
if matchFound eq 1 then begin
; if we get here, all file names match
; in first commonCount characters
break
endif
endwhile
if commonCount gt 0 then begin
result = strmid(result,0,commonCount)+'*'
endif else begin
; nothing in common, return wildcard
result = '*'
endelse
endif
return, result
END
{kind=link}
{kind=link}